游戏中的剔除分为很多个级别,比如背面剔除、视锥剔除、遮挡剔除,Early-Z,Z-Culling等等。在前面的文章中,我已经介绍过Early-Z的相关技术。这篇文章主要介绍游戏中的遮挡剔除相关算法,对于遮挡剔除,是比较难以实现的,因此我也不是全看懂了。。。在此总结一下一些常用的剔除算法。
在3D图形渲染中,大多数情况下离相机最远的物体首先呗渲染,接近的物体后渲染并覆盖先前渲染的物体,容易造成OverDraw。对于被其他物体遮挡但是依然在视锥体内的物体,不会被视锥剔除,所以遮挡剔除主要工作就是剔除被其他物体遮挡的物体。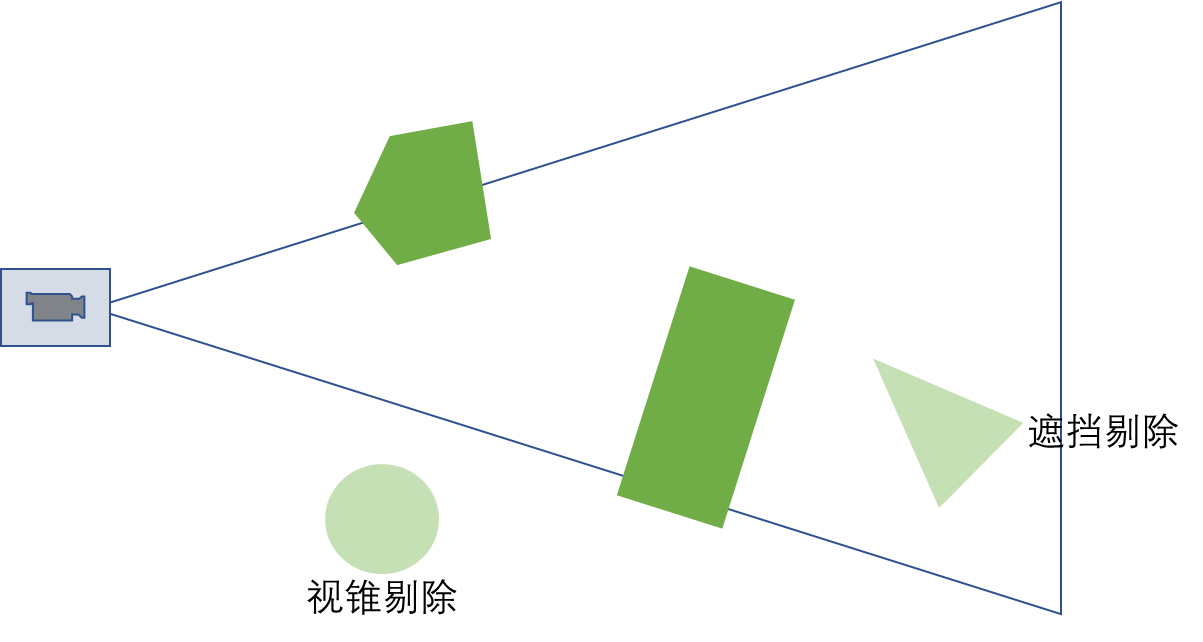
目前主流的遮挡剔除分为CPU端的和GPU端的。
CPU端:
- 预计算的原始的PVS
- Umbra的dPVS
- SoftWare Occlsion
GPU端:
- GPU-Driven
- Hierarchical Z-Buffering
1. 预计算原始的PVS()
预计算原始的PVS主要流程为先进行空间划分,把场景划分成多个规则的三位网格,然后离线计算每个格子内的所有物体的可见性状态,将信息序列化后保存并打包进游戏中。在运行时,根据相机当前的位置,读取所在网格的可见性信息,在CPU设置可见性并提交绘制。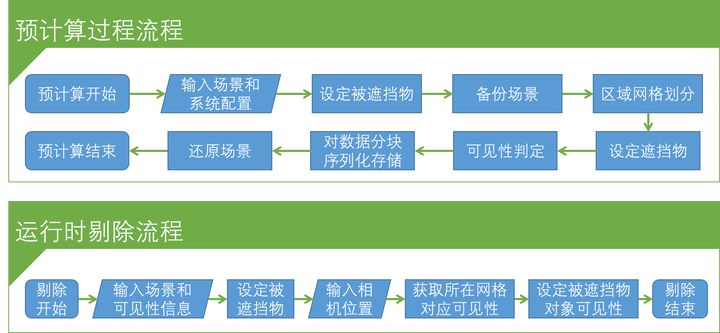
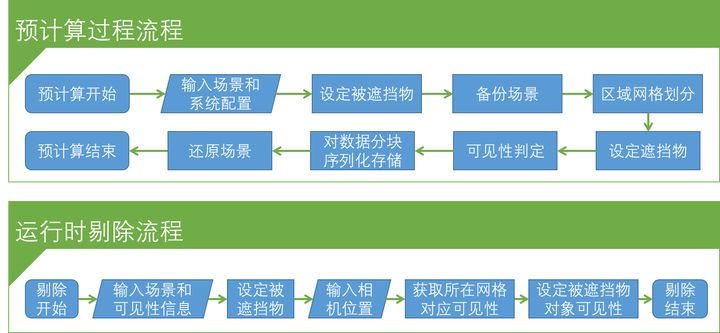
在预计算过程中,需要将区域网格划分。区域网格划分需要找到场景中相机可能达到的区域,并且将区域按照一定的规则划分成网格。
划分完三维网格后就进行可见性检测。主要思想是:在场景的遮挡物(Occluder)中,求解每个区域网格(Cell)到每个被遮挡物(Occludee)是否可见。
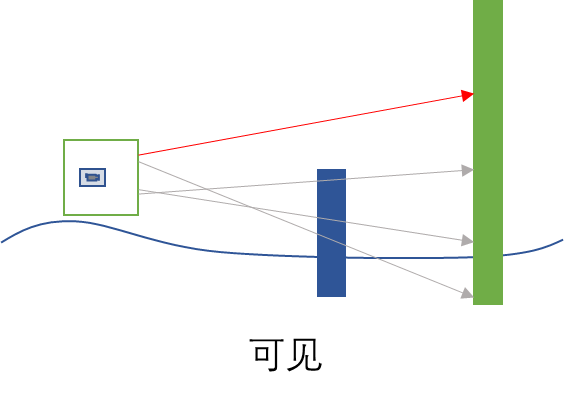
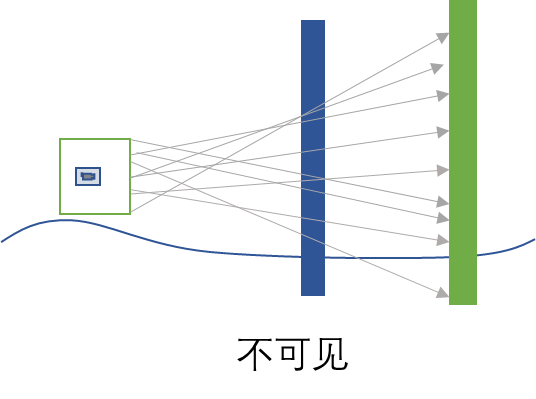
因此对每个网格进行可见性判定是很重要的。但是,每一对(网格到被遮挡物)的可见性判定,需要采样多少个光线,无法判定它们是否完全可见。在这里UE引擎采用了两个保守的方案来保证结果的正确性。一是将被遮挡物的模型包围盒扩大1.2倍来计算,二是在计算的时候用重要性采样(Importance Sampling)策略来补足:在所有光线都判定为不可见之后,将其中最长的前5% 的光线,随机偏转一个小角度。
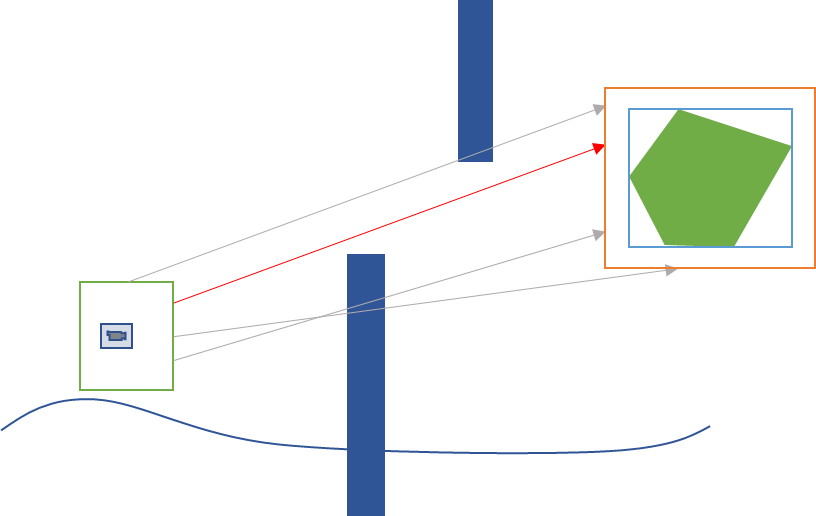
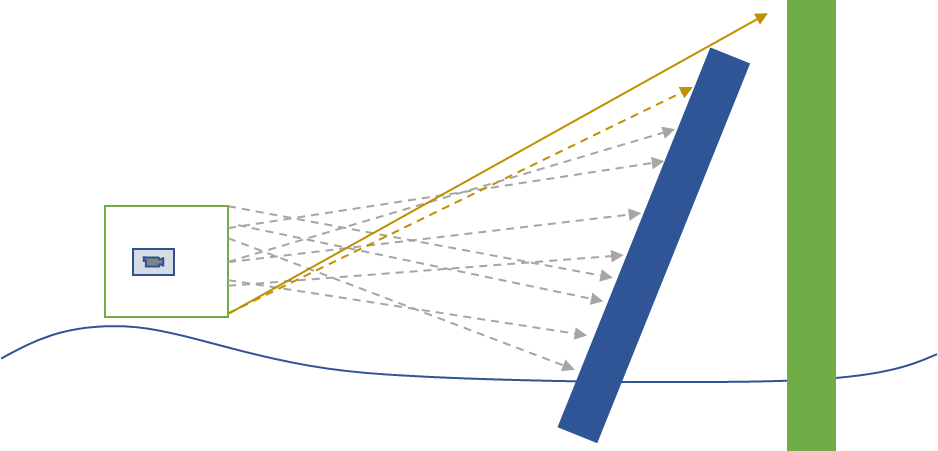
2. Portal-Culling()
这种方式也是将场景划分成Cell,不同的是,烘焙时保存的是每两个相邻Cell之间的连通性。这样,在运行时,根据摄影机所在的位置的Cell和观察方向,就可以根据Cell间的连通性信息,快速计算出目标物体是否处于可见范围内。当我们处于某一个节点的时候,只有那些和它相连的Cell才有可能被我们看到。运行时找到所有与它有Portal连接的Cell,没有Portal连接的所有Cell都可以直接被判定为不可见的从而被剔除。
使用这种方式最出名的方案就是Umbra的dPVS。
3. Software Occlusion
在运行时,将遮挡物的包围盒(或最高LOD级别的模型)软光栅到CPU内存中的z-buffer上,然后根据z-buffer中的深度信息,根据需要剔除物体的包围盒,实时计算遮挡信息。
4. Occlusion Query(遮挡查询)
Occlusion Query允许你在绘制命令执行之前,向GPU插入一条查询,并且在绘制结束之后的某个时刻,从GPU将查询结果回读到系统内存里。这条查询命令得到的是某次DrawCall中通过Depth Test的Sample数量,当这个Sample的数量大于0时,就表示当前模型是部分可见的,否则当前模型完全被遮挡。主要过程为:
- 用一个简单的depth only的pass绘制整个场景
- 每次绘制前后插入occlusion query的命令,并根据passed sample count去标记某个物体是否被完全挡住
- 执行正常的渲染流程,并剔除那些被标记为完全遮挡的模型
Occlusion Query主要有两个缺点:1.对于复杂的场景,即使只用简单的depth only pass也有很大的VS开销,可以用包围盒代替模型本身去做渲染。2.它需要将查询结果回读到系统内存里,这就意味着进行了从显存到RAM的操作,比较常用的的方法是让CPU回读前一帧的occlusion query的结果。
5. GPU Driven 的剔除
既然将GPU中的测试结果回传到CPU中需要很长的时间,那么可以直接将测试的结果保存在GPU中,然后直接根据剔除结果来选择是否绘制物体。GPU Driven Rendering Pipeline的核心思路是减少CPU和GPU之间的通信,尽量将所有渲染相关的事务都放在GPU端。
GPU-Dirven就是通过这样的思路来实现Indirect Draw。严格来说,GPU-Driven不是一种剔除算法,而是一种设计思路,其中的剔除部分仍然需要使用其他的算法来实现。
大致的流程为:
- 创建Indirect指令队列,将所有待渲染物体的渲染指令录入;
- 对渲染物体进行遮挡剔除,将剔除结果写入到buffer中(体现Computer Shader的用处);
- 根据buffer中的剔除结果,GPU会选择性执行录入的Indirect渲染指令,达到剔除的效果。
Hierarchical Z-buffer
在实现基于GPU的遮挡裁剪时,我们会使用到一种称为Hierarchical Z-buffer的技术,他是整个遮挡查询的关键所在。
Hierarchical z-buffer,即多Mip层级的z-buffer,每个更高级别Mip的buffer记录上一级别中周围四点中最远处的深度值。具体过程如下:
图中z = 0是近裁剪面,z = 1是远裁剪面。首先我们将遮挡物(红色和蓝色)进行光栅化,得到一个z-buffer,如下图竖着的那根灰色的线就代表了光栅化后的深度值。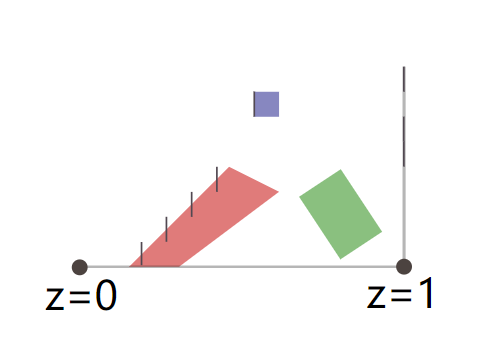
接下来采样z-buffer,得到一串mipmap层级贴图(这里采用下采样,使用的是max操作,也就是说两个相邻的像素下采样为一个像素时,使用两者中最大的那个的值作为下一层级的值)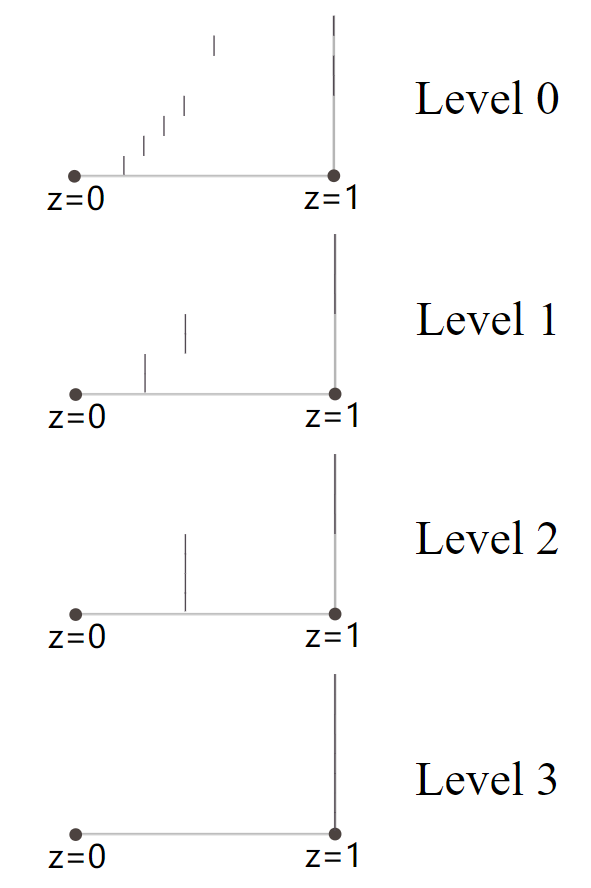
每一次下采样,都是对上一层级的保守估计,到了第4级就只剩下一个深度值了。由于下采样的时候用的是max操作,所以如果一个物体在level 2中深度值判定为被遮挡,那么它肯定在level 1中也是被遮挡的。
得到HiZ-buffer之后,我们就可以基于它来进行遮挡裁剪了:
计算得到绿色物体的AABB包围盒,该包围盒的x-max/min和y-max/min用来决定采样哪一层级的HiZ-buffer(也就是看哪一层级的尺寸能够涵盖包围盒的所有像素)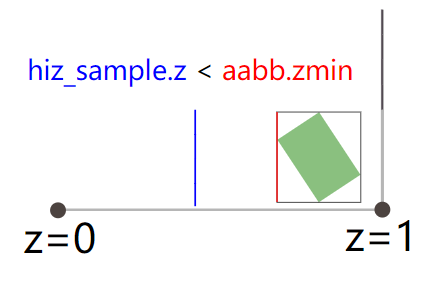
以上的方法就是基于Hierarchical Z-buffer的遮挡裁剪。可以看出如果没有HiZ-buffer,我们将不得不采样四个样本才能确定一个物体是否被遮挡了,HiZ-buffer大大减少了纹理采样的次数,提高了遮挡查询的效率。
参考
游戏中的遮挡剔除/Occlusion Culling
剔除:从软件到硬件
Software Occlusion Queries for Mobile
Hi-Z GPU Occlusion Culling
浅谈HiZ-buffer



